
߷ Implicit Ray-Transformers for Multi View Remote Sensing Image Segementation
Submittd to "IEEE Transactions on Geoscience and Remote Sensing"
Motivation
The mainstream segmentation methods benefit from the deep convolution neural networks (CNN), which can effectively learn and extract robust and discriminative features from the input images. However, deep CNN-based remote sensing image segmentation methods rely heavily on massive training data. As shown in Fig.(a), the performance of traditional CNN-based methods is sensitive to the number of annotations. A large number of high-quality pixel-wise annotations, as a guarantee for the performance of CNN-based segmentation methods, consume a great deal of time and effort. As for the task of semantic segmentation for a 3D scene given only limited annotated views, the CNN-based methods may overfit the views in the training data but generate poor results for the rest of the views. The key reason is that the 2D texture information or 2D context relationship is insufficient to identify similar-textured objects (Fig. (b)) in a 3D scene. Finally, the 3D context relationship of a scene is also crucial for semantic attribute prediction (Fig. (c)). For example, the building is typically higher than the road and the same object across different views usually has a similar texture. However, these properties have been rarely investigated in previous papers.
Abstract
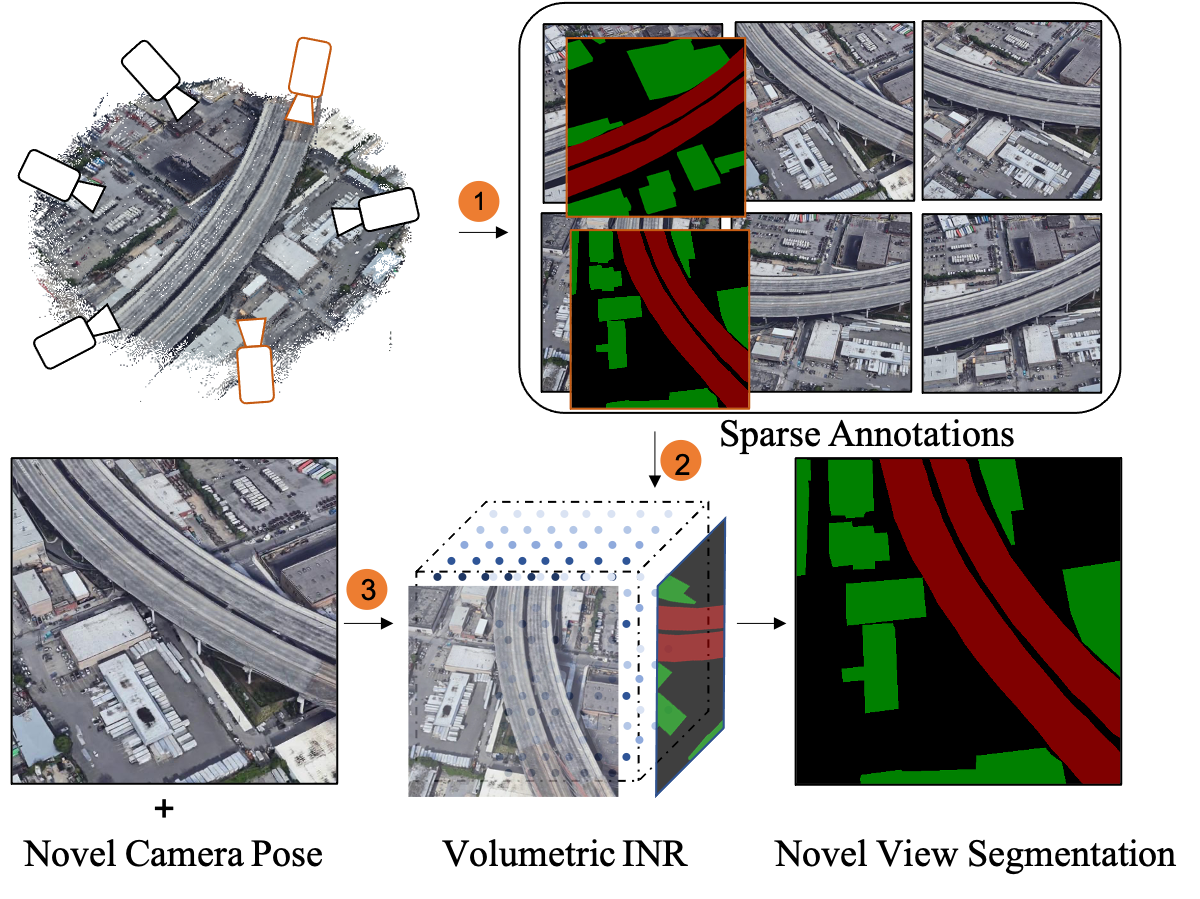
The mainstream CNN-based remote sensing (RS) image semantic segmentation approaches typically rely on massive labeled training data. Such a paradigm struggles with the problem of RS multi-view scene segmentation with limited labeled views due to the lack of considering 3D information within the scene. In this paper, we propose ``Implicit Ray-Transformer (IRT)'' based on Implicit Neural Representation (INR), for RS scene semantic segmentation with sparse labels (such as 4-6 labels per 100 images). We explore a new way of introducing multi-view 3D structure priors to the task for accurate and view-consistent semantic segmentation. The proposed method includes a two-stage learning process. In the first stage, we optimize a neural field to encode the color and 3D structure of the remote sensing scene based on multi-view images. In the second stage, we design a Ray Transformer to leverage the relations between the neural field 3D features and 2D texture features for learning better semantic representations. Different from previous methods that only consider 3D prior or 2D features, we incorporate additional 2D texture information and 3D prior by broadcasting CNN features to different point features along the sampled ray. To verify the effectiveness of the proposed method, we construct a challenging dataset containing six synthetic sub-datasets collected from the Carla platform and three real sub-datasets from Google Maps. Experiments show that the proposed method outperforms the CNN-based methods and the state-of-the-art INR-based segmentation methods in quantitative and qualitative metrics. Ablation study shows that under limited label conditions, the combination of the 3D structure prior and 2D texture can significantly improve the performance and effectively complete missing semantic information in novel views. Experiments also demonstrate the proposed method could yield geometry-consistent segmentation results against illumination changes and viewpoint changes. Our data and code will be public.
Pipeline

The proposed method has a two-stage learning process. We first optimize a color-INR of the target scene using multi-view RGB images, where the 3D context information is encoded in the weights of a set of MLPs. Then we employ a knowledge distillation strategy to convert color INR to semantic INR. In order to enhance the semantic consistency between multi-viewpoints. We design the Ray-Transformer to integrate and transfer the 3D ray-color features into ray-semantic features. Specially, we add a CNN texture token to broadcast texture information among different locations along a ray. Finally, we combine the 3D ray-semantic features from semantic-INR and 2D features from additional CNN to complete the missing semantic information in novel views and get more detail and accurate results.









Results

In this paper, we consider multi-view remote sensing image segmentation under sparse annotations and propose a new method based on implicit neural representation and transformer. We optimize the implicit volume representation of the 3D scene by fitting the posed RGB images into a neural network. Then a Ray-Transformer network combines the CNN features with the 3D volume representation to complete the missing information of the unknown views. To achieve this, we also introduce a challenging dataset for the R4S task. Extensive experimental results verify the effectiveness of our proposed method. The results demonstrate that our method outperforms other CNN-based methods in terms of both accuracy and robustness. We also compare different strategies to add texture information into INR feature space and show the effectiveness of the transformer structure for this task. Finally, our empirical results also indicate the robustness of our method against illumination and viewpoint changes in the scene.
Dataset
The complete dataset can be obtained from the link:https://drive.google.com/file/d/1p__6-RyVulNHHgc2VaGUVyYdGMWx-oig/view
More
More experiment results can be found in our paper
BibTeX
@misc{https://doi.org/10.48550/arxiv.2303.08401,
doi = {10.48550/ARXIV.2303.08401},
url = {https://arxiv.org/abs/2303.08401},
author = {Qi, Zipeng and Chen, Hao and Liu, Chenyang and Shi, Zhenwei and Zou, Zhengxia},
title = {Implicit Ray-Transformers for Multi-view Remote Sensing Image Segmentation},
publisher = {arXiv},
year = {2023}
}